
Not all generative AI models work the same way.
Some generate one word at a time in a sentence, others build images by gradually removing noise, and a few rely on two competing networks to refine their output.
Understanding the differences matters, especially when deciding which model fits a product, task, or budget. From large language models that power chatbots to diffusion systems used in design tools, each model architecture comes with tradeoffs in speed, accuracy, and flexibility.
This guide breaks down the main types of generative AI models in use today.
You’ll find examples of real tools built on each approach, how the models are trained, and where they’re best applied. Even if you're shipping features, testing ideas, or choosing between options, this will help you map model types to specific goals with more confidence.
What Are Generative AI Models?
Generative AI models are machine learning models that learn patterns from training data and use those patterns to produce new data. They can generate anything from paragraphs and charts to images, audio, or labeled samples.
Instead of assigning categories or predicting values, they build new examples that resemble the data they were exposed to.
These models require large volumes of training input: text, visuals, code, or structured tables, to identify relationships and common features. Once trained, they can produce outputs that share structure and meaning with the original content but aren't copied from it.
Their performance depends heavily on the diversity and scale of the training dataset.
Several types of generative models exist, each with a distinct learning method. Some rely on probability distributions and compressed representations. Others simulate noise and reverse it over multiple steps until a structured result appears. A few models approach the problem sequentially, predicting one element at a time.
The most common types include:
- Generative adversarial networks, which use two neural networks to push each other toward better output
- Variational autoencoders, which compress complex data into a latent space and draw new samples from it
- Diffusion models, which gradually turn random noise into refined results
- Autoregressive models, which handle sequential data by predicting each next piece based on prior context
Recent advances in foundation models and transformer-based tools have extended the reach of generative AI.
By training on massive, varied input collections, these systems can now support industries that rely on large volumes of generated content, from product design and video creation to analytics and customer-facing automation.
How do Generative Artificial Intelligence Models Work?
Generative AI models produce new content by learning patterns from training data. Instead of predicting a fixed answer, they create generated output based on the relationships between values in the input data.
To do this, the model processes thousands or millions of examples.
It learns how parts of the data connect, such as how pixels form shapes or how words follow each other in a sentence. From that, it can generate textual data, synthetic images, or other AI-generated content.
Each model type builds its output differently:
- Autoregressive models generate one step at a time, common in text generation
- VAEs compress and sample from latent space to produce variation
- GANs train two neural networks, one to create, one to evaluate
- Diffusion models start with random noise and refine it gradually
Most use either compressed representations, sequential prediction, or reverse diffusion. These methods help models handle complex data and produce realistic synthetic data across formats.
7 Types of Generative AI Models

Generative Adversarial Networks (GANs)
GANs are among the most recognized generative models, especially in fields like image generation and video synthesis. These models use two neural networks trained together. One generates data, and the other tries to detect whether it’s fake or real. This constant competition pushes both networks to improve over time.
The generator learns to produce realistic synthetic data, while the discriminator aims to distinguish that from original data. Both networks adjust based on the other’s output.
When trained competently, the result is high-quality data that resembles the training input closely.
GANs are usually used to generate images, improve resolution, or simulate complex visual scenes. Since they don’t rely on labeled data, they can be useful for data augmentation or tasks where labeled examples are limited.
GANs are also part of deep generative models that contribute to more comprehensive systems, including computer vision applications.
Variational Autoencoders (VAEs)
VAEs work by compressing input data into a smaller, structured format known as latent space.
From there, the model samples and decodes that information to produce new outputs. Instead of aiming for sharp realism like GANs, VAEs focus on generating smooth, consistent variations across data points.
Each VAE is trained using a combination of reconstruction loss and probability distribution alignment. This helps the model balance accuracy with variability. The outputs aren’t identical to the original data but share enough structure to be useful.
VAEs are applied in text generation, anomaly detection, and structured image generation.
Because they model uncertainty directly, they’re helpful in applications where variation matters. These models are especially useful in research settings or when building systems that need to generate synthetic data while preserving important features from the training dataset.
Autoregressive Models & Transformers
Autoregressive models predict the next value in a sequence based on everything that came before it. This logic supports text generation, code completion, and many language modeling tools. Every output depends on earlier predictions, which makes error handling and context memory critical.
To train generative models like this, teams use structured sequences pulled from large-scale textual datasets. Each token is linked to the one before it, forming a probability chain. This makes autoregressive models especially useful for working with language, where order defines meaning.
Transformer-based models follow a similar logic but scale it.
Instead of processing one element at a time, they analyze entire sequences using attention. That mechanism allows models to make smarter predictions on long text blocks. It also made it possible to build the large language models used today in search, chat, and content generation.
When built on deep neural networks and trained on massive datasets, transformer-based systems support everything from summarization and translation to AI-generated code and natural conversation.
The architecture is now used in many foundation models, helping generative AI platforms.
Diffusion Models
Diffusion models follow a step-by-step process. They begin with random noise and remove it in stages until the result resembles real-world data. The number of steps varies by model, but the idea remains the same: recover structure by undoing disruption.
To make that possible, the model first learns how noise affects the original data.
It gets trained on clean samples and noisy versions of the same inputs. Over time, it learns how to reverse the process. Each iteration brings the output closer to something usable.
In image generation, this method can produce highly detailed visuals, even from vague starting points. Models like Stable Diffusion use this technique to generate synthetic data that mirrors artistic styles, human faces, or product mockups.
It doesn’t require labeled data, so it’s also helpful in synthetic data generation, especially for startups looking to build a no-code SaaS with rich visuals, and tasks like data augmentation or anomaly detection.
Among the most common types of generative AI models, diffusion techniques are now used in both research and production environments. Their reliability and flexibility make them a standard option for high-resolution image tasks and creative experimentation.
Flow-Based Models
Flow-based models generate content by learning how to map simple distributions into complex ones and back again. Not like systems that rely on sampling or refinement, these models build a two-way path between raw input and generated output using exact probability calculations.
The method depends on modeling how data transforms from structured input into a normalized space.
Every transformation step is reversible. That makes flow-based systems useful for inspecting how input data relates to the output, giving them a level of transparency that other generative models don’t offer.
They’re frequently used in fields where interpretability matters, like anomaly detection or data compression. Because the probability distribution is explicitly modeled, it’s easier to understand how the system reaches each result.
Compared to other types of generative AI models, flow-based tools remain less common in production settings but are valuable for research and smaller batch generation tasks. These models also have potential applications in structured environments like enterprise resource planning (ERP), where reversibility and transparency are mission-critical.
Recurrent Neural Networks (RNNs)
Recurrent neural networks are designed to process sequential data.
Each layer feeds information to the next while looping context back into earlier steps. That structure helps the model retain memory over time, which is essential for data involving order, rhythm, or conversation.
RNNs were among the first generative models used in language applications.
Early systems for text generation, predictive typing, and voice synthesis often relied on this architecture. Although newer transformer-based models have replaced many RNNs in production, these systems still help train lightweight models and support embedded AI tasks.
Their strength lies in recognizing short-term patterns within training datasets, especially when inputs come in continuous streams. RNNs can generate synthetic data, model time-series behavior, or assist in predictive modeling where context changes frequently.
Large Language Models (LLMs)
Large language models are built to process and generate textual data at scale. These systems are trained on massive training data sets, often spanning books, articles, codebases, and dialogue.
Their size allows them to handle complex syntax, long-range context, and subtle variation in tone or intent.
Most LLMs are based on transformer architectures and rely on autoregressive techniques. They analyze sequences of input text and predict what comes next, generating responses, summaries, or creative output with relatively high accuracy, and can be combined with retrieval augmented generation (RAG) for grounded outputs.
LLMs belong to a broader category of foundation models that serve multiple use cases. Generative models are even powering tools like an AI website builder, where user prompts transform into fully developed front-end layouts.
Their outputs include everything from chatbot responses and documentation drafts to synthetic data generation for downstream AI models. The ability to generate increasingly realistic data at scale makes them one of the most popular generative AI models in production today, including for advanced use cases like agentic AI.
Key Differences Between Generative AI Model Types
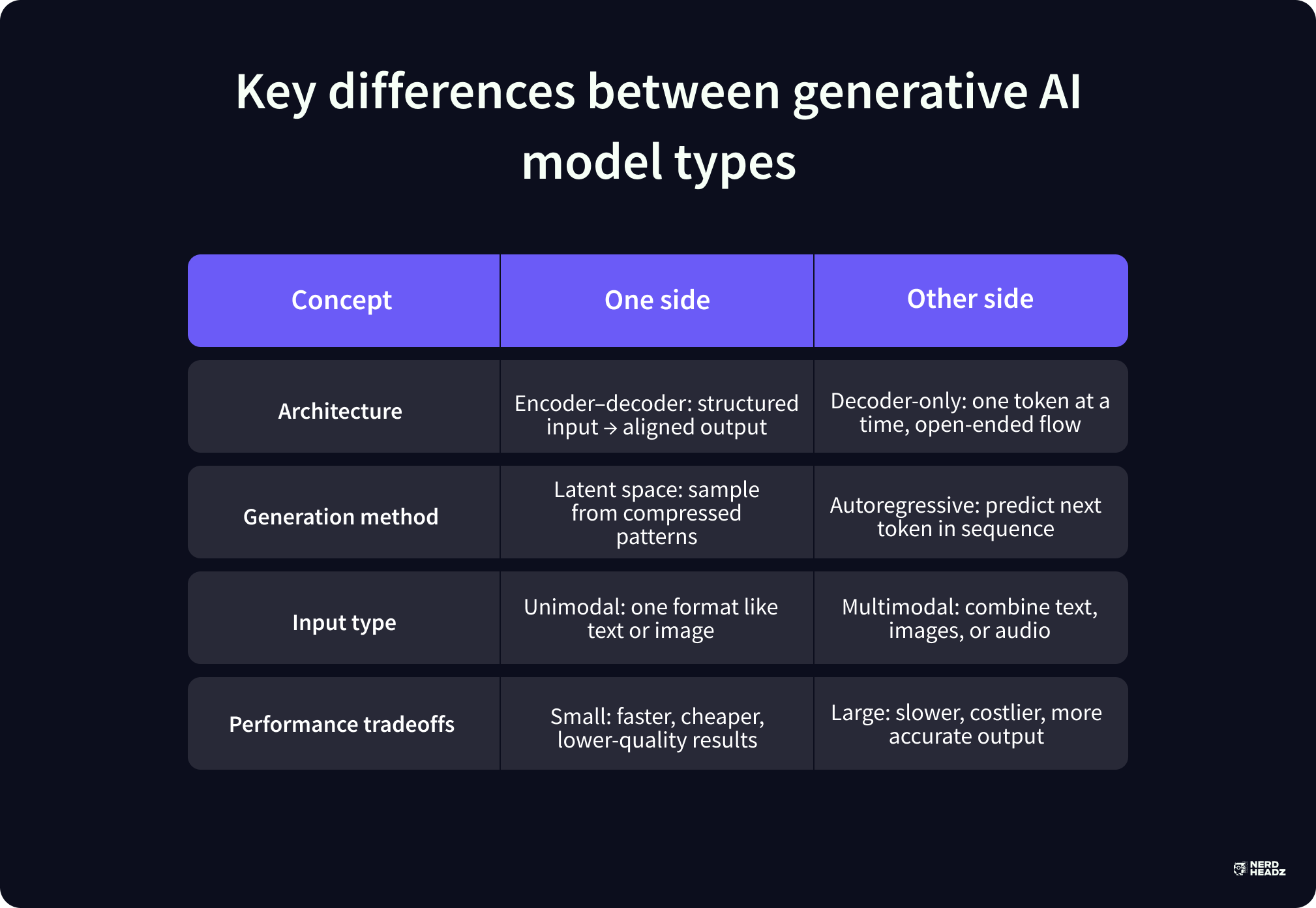
Encoder–Decoder vs Decoder–Only Structures
Some generative models process the input all at once. Others generate output step by step, using only what’s already been written to inform the next part. That difference in structure affects how well a model handles prompts, context length, and response relevance.
Encoder–decoder models separate the process into two stages.
First, the encoder takes the input, text, image, or other format, and converts it into a compressed internal signal. That representation holds meaning, structure, and position within the data.
The decoder then uses that signal to produce a new output, often closely tied to the original. This method supports applications that depend on full-context understanding, such as translation, summarization, and long-form question answering.
Decoder-only models don’t rely on a fixed input. They generate one token at a time, each based on what’s already been produced. The system predicts what comes next, word by word, until the full output is complete.
Here’s how the two compare:
- Encoder–decoder models perform well on tasks with clear input–output relationships
- Decoder-only systems are built for flexibility, handling long sequences with fewer constraints
Choosing between the two depends on the output goal, tight alignment with original data, or open-ended generation at scale.
Latent-Space Sampling vs Autoregressive Token Prediction
Different generative models use different strategies to build output. Some compress training data into dense internal maps, while others rely on sequence-based prediction.
These guidelines structure how variation, accuracy, and structure are held during generation.
Latent-space sampling starts with compression. The model transforms input into a latent representation, reducing complexity while preserving key patterns. It then draws from that internal space to create new outputs. Variational autoencoders follow this method.
The result is synthetic content that reflects the training distribution without repeating it. That structure supports use cases like anomaly detection, probabilistic modeling, and structured synthetic data generation.
Autoregressive prediction doesn’t compress. It generates one token at a time, each based on the sequence that came before. This method underpins most text-focused systems, including large language models trained on web-scale datasets.
The model treats content as a chain, where every new word depends on the context established by earlier ones.
Key differences between the two include:
- Latent-space methods control variation by sampling from compressed patterns
- Autoregressive models generate fluid, context-aware sequences in real time
Both techniques appear across different types of generative AI models, depending on the balance between structure, speed, and variability required.
Unimodal vs Multimodal (Image, Text, Video) Generative Models
Not all generative models handle the same type of input. Some are trained on a single modality. Others are built to work across formats, generating outputs that combine visual, written, or audio data.
Unimodal generative models specialize in one type of input and output. That could mean generating images from image data, writing text based on previous text, or modeling audio patterns from waveform data. These systems are often smaller, more focused, and easier to tune.
Most image generation models like Stable Diffusion, or early large language models built for text generation, fall into this category.
Multimodal models process and generate across multiple input types. They might generate captions from images, create realistic images from prompts, or describe videos using natural language.
Key distinctions between the two include:
- Unimodal models are simpler to train and usually produce more sensitive results within their specific domain
- Multimodal systems handle more expansive tasks but demand larger datasets and more compute to maintain precision in all modes
Parameter Size, Compute Requirements, & Latency Tradeoffs
Generative AI systems vary in size, from lightweight models that run on a laptop to massive architectures requiring clusters of GPUs.
Larger models generally include more parameters, deeper neural network layers, and broader access to patterns within the training dataset. They tend to perform better on nuanced tasks like abstract text generation or creative composition.
However, with size comes cost. These systems need longer training times, more data-based preprocessing, and significant infrastructure to support inference.
Smaller models reduce those demands, but sacrifice output quality in return.
They may generate content faster, but struggle with long-form structure or cross-topic consistency. Latency becomes a critical issue for real-time use cases like chat tools, product recommendations, or any feature requiring low wait times. These decisions often mirror the tradeoffs seen in custom software development vs. in-house teams, where scalability and latency must align with business goals.
To balance these needs, teams usually consider:
- Parameter count, which affects memory usage and prediction accuracy
- Compute requirements, including GPU availability and batch size
- Latency expectations, tied to how fast a user sees results from input to generated output
These performance-cost tradeoffs are also critical when teams plan how to make a budget for software development, especially with AI’s variable compute costs.
Generative AI Model Use Cases With Real Examples
GPT‑4o, Claude 3, Llama 3: Best for Chatbots, Agents, & Language Tasks
Generative models built for conversation rely on high-quality training data, token prediction accuracy, and context memory. GPT‑4o, Claude 3, and Llama 3 are built on transformer-based models designed to work with long sequences and subtle variations in text.
These systems support everything from live chat to in-product guidance. For industry-specific insights, see which industries gain the most from chatbot applications.
Each of them uses autoregressive models to generate text one token at a time. This method helps maintain tone, flow, and accuracy over multi-turn interactions. The ability to handle diverse language styles is critical for applications like support bots, documentation tools, or coding assistants.
Use cases include:
- Drafting written content from minimal prompts
- Assisting with data exploration using natural language interfaces
- Generating documentation or internal knowledge summaries from existing input
The systems behind these outputs are trained on massive labeled and unlabeled datasets.
Each layer in the model architecture contributes to context retention and relevance across outputs. As a result, these language models now support teams across SaaS, research, education, and product development.
Stable Diffusion 3.5, Imagen 4: Best for Text-to-Image Generation
Text-to-image generation works by translating natural language descriptions into visual data points. Stable Diffusion 3.5 and Imagen 4 lead this category of AI visual development. Both models use diffusion-based architectures trained on image-text pairs.
The process starts with random noise and gradually applies reverse diffusion steps to form structure, color, and detail.
Each version improves on its previous model’s performance by adjusting sampling methods, refining noise reduction, and scaling latent space resolution, frequently used in projects that require custom software development. Because the training data includes millions of captioned visuals, these models learn how visual elements correlate with written prompts.
Used in areas like:
- Marketing teams building concept visuals from briefs
- Product design workflows that require fast iteration
- Internal tooling for synthetic data generation or mockups
These models don’t require labeled data in the traditional sense.
They generate images by learning statistical patterns in visuals and descriptions, then applying those patterns to create new combinations that match the prompt with surprising accuracy.
Veo 3: Best for Generating Video From Text Descriptions
Veo 3 is one of the few generative AI models built specifically for video.
It turns text prompts into short clips with fluid motion, consistent detail, and scene logic. The system uses transformer-based models combined with diffusion techniques to guide generation across frames.
Far from image generators, which only need to connect static pixels, video generation requires understanding how objects interact over time.
Veo 3 approaches this by training on paired datasets of video segments and natural language prompts, similar to stages in the software development lifecycle (SDLC). The model architecture learns how descriptions map to physical motion, setting, and pacing.
Key use cases include:
- Concept development for commercial video production
- Early-stage ideation for film, animation, or game design
- Internal asset generation for testing or pitch decks
The model receives input data as written language, then translates that into movement, layout, and shot transitions.
Over multiple passes, it refines visual elements using patterns learned during training.
Veo 3 represents a different class of generative models, built for video rather than static output, with strong results across industries focused on visual storytelling. Some of the best online marketplace examples use diffusion-based AI to create dynamic listings or enhance user visuals.
Phi‑4 Mini, Flash: Best for Lightweight On-Device AI Experiences
Phi‑4 Mini and Flash are compact language models designed for fast, low-power environments. These systems are trained to work without heavy infrastructure and are optimized for use cases where real-time response is important and bandwidth is limited.
Both models use scaled-down versions of autoregressive architectures.
The goal isn’t to outperform large language models on every task, but to respond quickly and reliably in local settings. These tools are deployed in mobile apps, embedded systems, or edge devices.
Common applications include:
- Writing suggestions inside note-taking or productivity tools
- Offline chat assistance or AI-generated summaries
- Input refinement for text-based commands or search
Even with fewer parameters, these models are capable of handling meaningful text generation tasks.
Their design emphasizes latency, memory efficiency, and portability. When trained with domain-specific datasets, they can perform well in tightly scoped contexts where accuracy and speed matter more than open-ended reasoning.
As lightweight generative AI models gain adoption, they fill a critical gap between large-scale cloud systems and localized embedded tools, delivering real utility without high compute costs.
GANs & VAEs: Best for Synthetic Data, Anomaly Detection, & Latent Sampling
Generative adversarial networks (GANs) and variational autoencoders (VAEs) are used in machine learning workflows that require synthetic examples for testing, training, or exploration. Each model works differently, but both allow teams to generate new data that follows patterns found in real datasets.
GANs rely on two neural networks trained together. One creates new samples, the other evaluates them against the original input.
Over time, the model improves its ability to produce content that becomes harder to distinguish from actual data. This method supports industries where data privacy is critical or where collecting labeled examples is expensive.
VAEs work through compression. The model maps input into latent space and samples from that compressed structure to generate new content.
While the results may not fit the acceptable detail of GANs, VAEs offer better control over variation. This makes them a strong fit for anomaly detection, where understanding the structure of normal input helps reveal outliers.
Use cases include:
- Creating artificial examples to expand small datasets
- Training classifiers on generated data without real-world exposure
- Sampling variations for probabilistic modeling and simulation
These tools are also frequently used when generating data for testing a minimum viable product (MVP) without exposing early users to incomplete features. Understanding MVP vs prototype distinctions can help determine where generative data should be applied during product validation.
Diffusion Models: Best for High-Fidelity Image and Video Generation
Diffusion models generate content by starting with noise and refining it step by step into clear, detailed output. The process is guided by patterns learned during training, using text, images, or both.
Each phase reduces randomness and moves the data closer to something that resembles real input.
In image generation, it can more consistently capture textures, lighting, and spatial coherence than earlier models. When applied to video, the model processes frame relationships to maintain temporal consistency.
Used in:
- Concept visualization across design and advertising
- Synthetic image generation for e-commerce or editorial mockups
- AI-generated animation previews or video snippets for storyboarding
Models based on this architecture have become popular in creative industries because they produce realistic images without requiring labeled training data. These features highlight some of the no-code development benefits for small businesses & startups, especially those building design-heavy tools or testing new visual products.
The ability to create increasingly realistic data from varied prompts, textual or visual, makes diffusion one of the most practical types of generative AI models for high-fidelity use cases.
Transformers & LLMs: Best for Text, Code, and Sequential Data Generation
Transformer-based models are the backbone of most modern large language models (LLMs).
They’re trained on massive datasets made up of text, code, and structured sequences. The architecture allows these models to predict what comes next in a sequence, while also maintaining awareness of earlier input, even over long spans.
LLMs powered by transformers are now used in search, chat interfaces, content tools, and writing assistants. The architecture supports parallel processing, which helps with performance and accuracy.
These models also play a growing role in enterprise app development, especially for teams that need smart document handling, chat automation, and internal knowledge systems.
Instead of moving one word at a time, the system can look across an entire prompt to identify patterns before generating a response.
Use cases include:
- Text generation for summarization, drafting, and rewriting
- Code completion inside integrated development environments
- Structured content production based on user prompts
These models rely on labeled and unlabeled training data across many domains. Some CRM tools even integrate with models like this, learn more about how to build a CRM with no-code using generative AI.
When trained with enough variation, they can generate increasingly realistic data across a wide range of outputs, such as email responses, documentation, scripts, or conversations. Outputs from LLMs can also assist in best practices for QA testing, especially in generating automated test scripts or synthetic data to validate system responses.
RNNs: Best for Time-Series or Audio Generation in Niche Applications
Recurrent neural networks (RNNs) are built for data that comes in sequences. They’re designed to retain short-term memory across steps, which allows them to model rhythm, tempo, and order.
Although newer architectures have replaced them in many use cases, RNNs are still useful in areas where time and signal continuity matter more than large-scale inference.
Because RNNs process one element at a time, they can be applied to time-series data or audio where small variations affect the whole outcome. They’re also easier to deploy when resources are limited or where deep model depth isn’t required.
Used in:
- Audio pattern generation for music, voice, or effects
- Modeling signals in financial or industrial forecasting
- Embedded AI tasks with limited memory or compute constraints
RNNs remain part of the broader landscape of generative models, especially where full-sequence memory and signal-based prediction offer clear advantages.
Flow-Based Models: Best for Exact Density Modeling and Reversible Transformations
Flow-based models map input data into a simpler space and then learn how to reverse that process exactly.
Different from other gen models that rely on sampling or stepwise refinement, flow-based systems preserve every transformation step, allowing for full reconstruction of both the input and the generated output.
They are used in scenarios where exact probability estimates are needed. Because the transformations are invertible, engineers can track how one data point moves through the network and verify how it changes shape.
Use cases include:
- Generating synthetic data with traceable probability distributions
- Building interpretable AI models for science or regulated domains
- Modeling real-valued structured data in finance or healthcare
Although less common than GANs or transformers, flow-based models offer advantages in control and reversibility. Their structure makes them valuable in systems that prioritize transparency and statistical alignment between the training data and the generated content.
Conclusion
Generative AI covers far more than chat interfaces or photo editing. Behind every use case, writing, design, simulation, prediction, there’s a specific model architecture doing the work. Each one processes structure, input, and output in its own way. This is also why comparisons like no-code vs full-code software development matter when deciding how AI capabilities get implemented in real products.
Some models, like transformers and autoregressive systems, focus on language and code. Others work with compressed signals in latent space or generate visuals by reversing noise over time.
Even lightweight systems like RNNs and flow-based models still support projects that need memory efficiency or strict interpretability.
Choosing the right model is about understanding how each one works with data, how it produces output, and where it fits into a broader product experience. If generative AI is part of your product roadmap, it’s worth reviewing the important factors to weigh when choosing a custom software development partner that understands these tradeoffs.
If you’re exploring generative AI for your platform, or building tools that rely on text, image, or synthetic data generation, get in touch with NerdHeadz. We’ll help you match the right model to your product, and build it the way your users actually need.


