01 / 06
RAG systems
Retrieval-augmented generation grounded in your data. Vector indexes, hybrid search, re-ranking, and answers that cite sources — not hallucinate them.
RAG systems, autonomous agents, voice AI, multi-agent orchestration — and the unglamorous plumbing that keeps them from hallucinating in production. Vibe-coded when speed matters, hand-crafted when reliability does.
Most "AI agents" are demos. Ours ship to production, call real tools on real data, and get caught when they're wrong — on purpose.
Retrieval-augmented generation grounded in your data. Vector indexes, hybrid search, re-ranking, and answers that cite sources — not hallucinate them.
Agents that plan, call tools, observe results, and loop until the job is done. Function calling, MCP, guardrails, and human-in-the-loop where it matters.
Specialist agents coordinating on a task — a planner, a researcher, a writer, a critic. Shared memory, message passing, deterministic hand-offs.
n8n and custom workflows that stop being dumb pipelines and start making decisions. Trigger on anything, reason about it, act on dozens of systems.
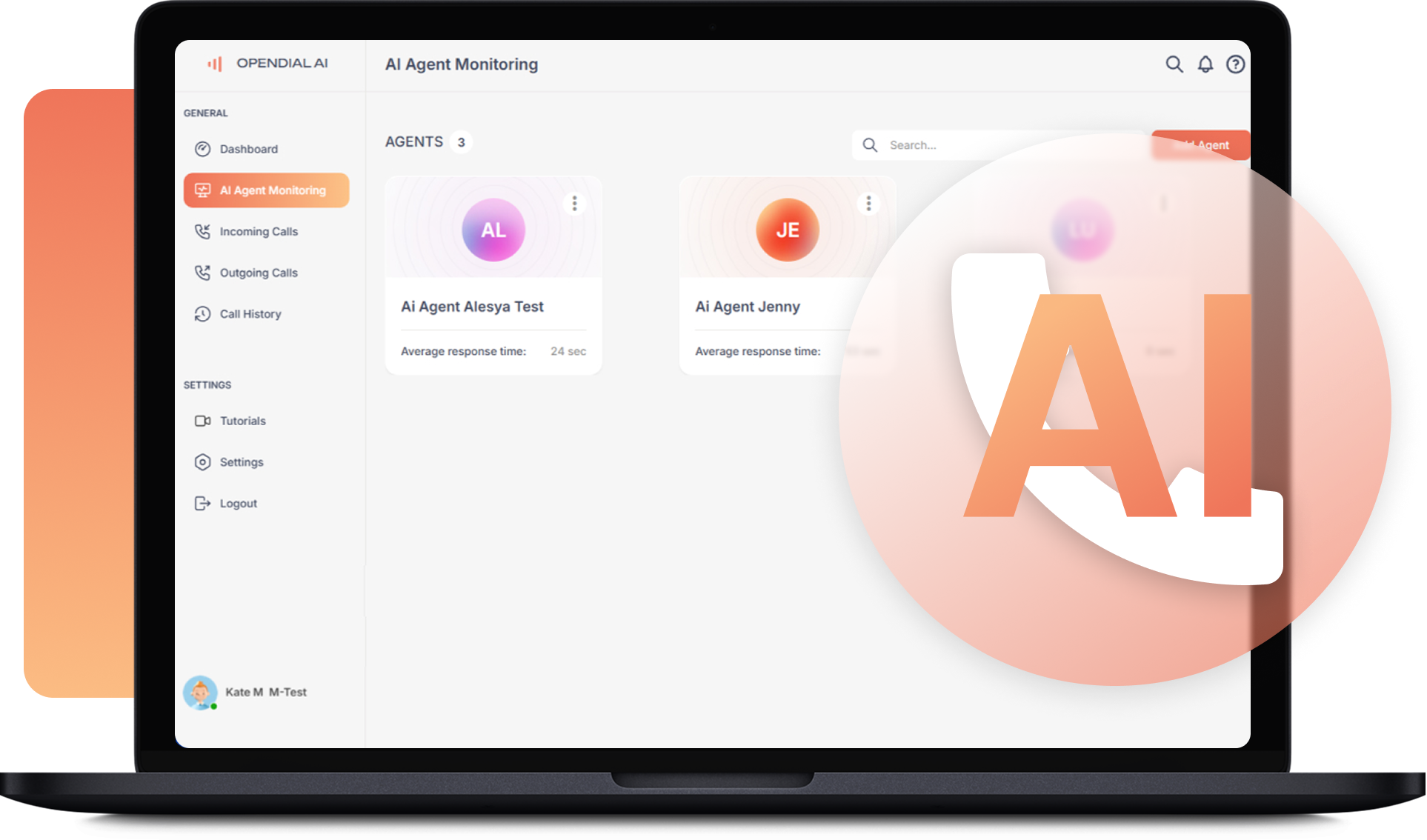
Real-time voice AI for inbound + outbound calls. Sub-second latency, interruption handling, CRM writebacks, and transcripts your ops team actually uses.
Full-stack AI products — auth, billing, dashboards, the works. Built to scale, built to ship. Vibe-coded when it helps, hand-crafted when it matters.
AI agent development is the practice of building software that autonomously performs multi-step tasks — not just answering questions, but taking actions. An AI agent calls APIs, queries databases, makes routing decisions, and executes workflows with minimal human intervention. At NerdHeadz, AI agent development means shipping production-grade agentic systems that plug into your existing stack, not demo-stage prototypes that work on a conference slide.
The difference between an agent and a chatbot is autonomy. A chatbot responds to prompts. An agent decides what to do next, picks the right tool, handles failures, and reports back when the job is done or when it needs a human decision. That distinction matters because it changes everything about how you build, test, and monitor the system. Agents that can take real actions — sending emails, updating records, scheduling meetings, writing to databases — require guardrails and observability that chatbots don't. Our stack for agent development is TypeScript and Python on the backend, React and Next.js when the agent needs a human-facing interface, and Claude Code accelerating the build itself.
Discovery. One to two weeks. We define the agent's boundary: what it's allowed to touch, what tools and APIs it needs, and what happens when it's wrong. Agent failure modes are different from chatbot failure modes — a chatbot that hallucinates gives a bad answer; an agent that hallucinates takes a bad action. We map every action surface and build the failure-mode inventory before writing code.
Prototyping. One to two weeks. We build a narrow-scope agent first — one workflow, one tool set, human-in-the-loop on every action. We measure task-completion rate against your real data before expanding scope. If the agent can't reliably complete the narrow task, adding more capabilities won't fix it. This is where most "agentic AI" projects should start and where many of them should stay — a focused agent that does one thing well is worth more than a general-purpose agent that does ten things unreliably.
Build. Three to eight weeks. Framework choice depends on the problem: LangGraph for stateful multi-step workflows, Claude's native tool use for simpler orchestration, custom orchestration when off-the-shelf frameworks add complexity without value. Observability and tracing ship on day one — not as an afterthought. Every agent call is logged with input, tool selections, outputs, and cost. Retries, fallbacks, and timeout handling are first-class concerns, because agents that silently fail are worse than agents that loudly refuse.
Handoff. Your team gets the runbook, the eval harness, and full ownership of prompts and tool definitions. Agents evolve faster than static software — new models, new tool capabilities, new edge cases from production traffic. The eval harness lets your team measure whether prompt changes improve or regress task-completion rate without guessing. We also include cost monitoring dashboards, because agent systems that call models in loops can generate surprising bills if usage patterns shift.
AI agents work well for a specific set of problem shapes — and fail predictably on others.
- Works well: multi-step workflows with clear success criteria — scheduling, triage, data enrichment, document processing pipelines, automated reporting. Tool-heavy tasks where the agent's value is orchestration across systems, not independent judgment. Internal tools where occasional human review on edge cases is acceptable and expected. - Usually doesn't work: single-turn Q&A (use a chatbot instead), high-stakes decisions without human review, tasks the underlying model can't do reliably in a single call. Agents amplify model weaknesses — they don't fix them. - Doesn't work: replacing judgment in regulated decisions, full autonomy over anything that spends money or sends external communications without guardrails, "an agent that just does my whole job." If someone pitches you that, they're selling you a liability.
AI agent development is one specialization within our broader AI development services. Depending on what you're actually building, one of these may fit better:
- If the core need is conversational — answering questions, handling support tickets, qualifying leads — AI chatbot development is the right framing. Agents and chatbots share infrastructure but differ in scope and risk profile. - If the agent needs to retrieve and reason over your company's documents, RAG & LLM development handles the retrieval layer that feeds the agent's context. - For teams that need a full product built with AI as a core capability, custom software development covers end-to-end delivery. - We build all AI agent projects using AI-assisted development workflows — Claude Code handles the routine engineering so our team focuses on the agent-specific concerns: tool design, orchestration logic, and evaluation.
Scripted, deterministic, and narrated like production logs — because that's how we build them. Every tool call observable, every decision auditable, every hallucination catchable before a user sees it.
It works well for a specific set of problem shapes — and fails predictably on others.
Multi-step workflows with clear success criteria — scheduling, triage, data enrichment, document processing pipelines, automated reporting. Tool-heavy tasks where the agent's value is orchestration across systems, not independent judgment. Internal tools where occasional human review on edge cases is acceptable and expected.
Single-turn Q&A (use a chatbot instead), high-stakes decisions without human review, tasks the underlying model can't do reliably in a single call. Agents amplify model weaknesses — they don't fix them.
Replacing judgment in regulated decisions, full autonomy over anything that spends money or sends external communications without guardrails, "an agent that just does my whole job." If someone pitches you that, they're selling you a liability.
We create intelligent agents that perform tasks effectively, adapt to diverse environments, and improve operational efficiency.
Our team automates repetitive processes to improve speed, reduce errors, and save resources for more work.
We design systems that interpret real-world inputs, ensuring decisions and operations remain relevant and impactful.
Our solutions enable systems to understand and process human language, facilitating smooth and natural communication with users.
We develop collaborative agents that efficiently handle complex tasks and achieve shared goals.
Our systems adjust to changing conditions instantly, maintaining consistent performance and reliability in dynamic environments.
We build platforms that connect our AI solutions with your existing tools, ensuring smooth transitions and heightened capabilities.
We implement advanced safeguards to protect your data and operations, ensuring safety and trust in every interaction.







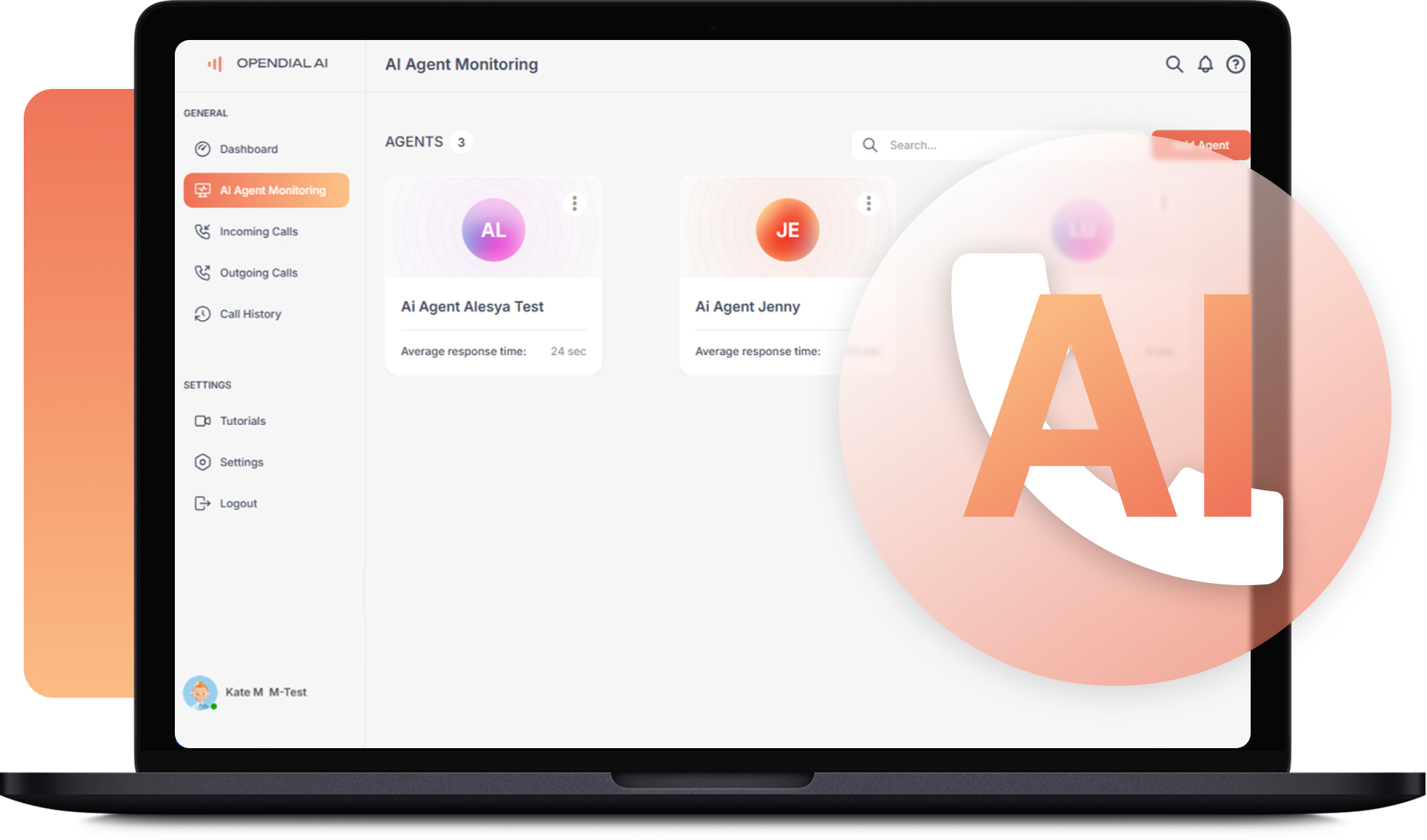
Inbound + outbound calls handled by LLM-powered voice agents. Triage, routing, CRM updates, and escalation to humans when trust matters.
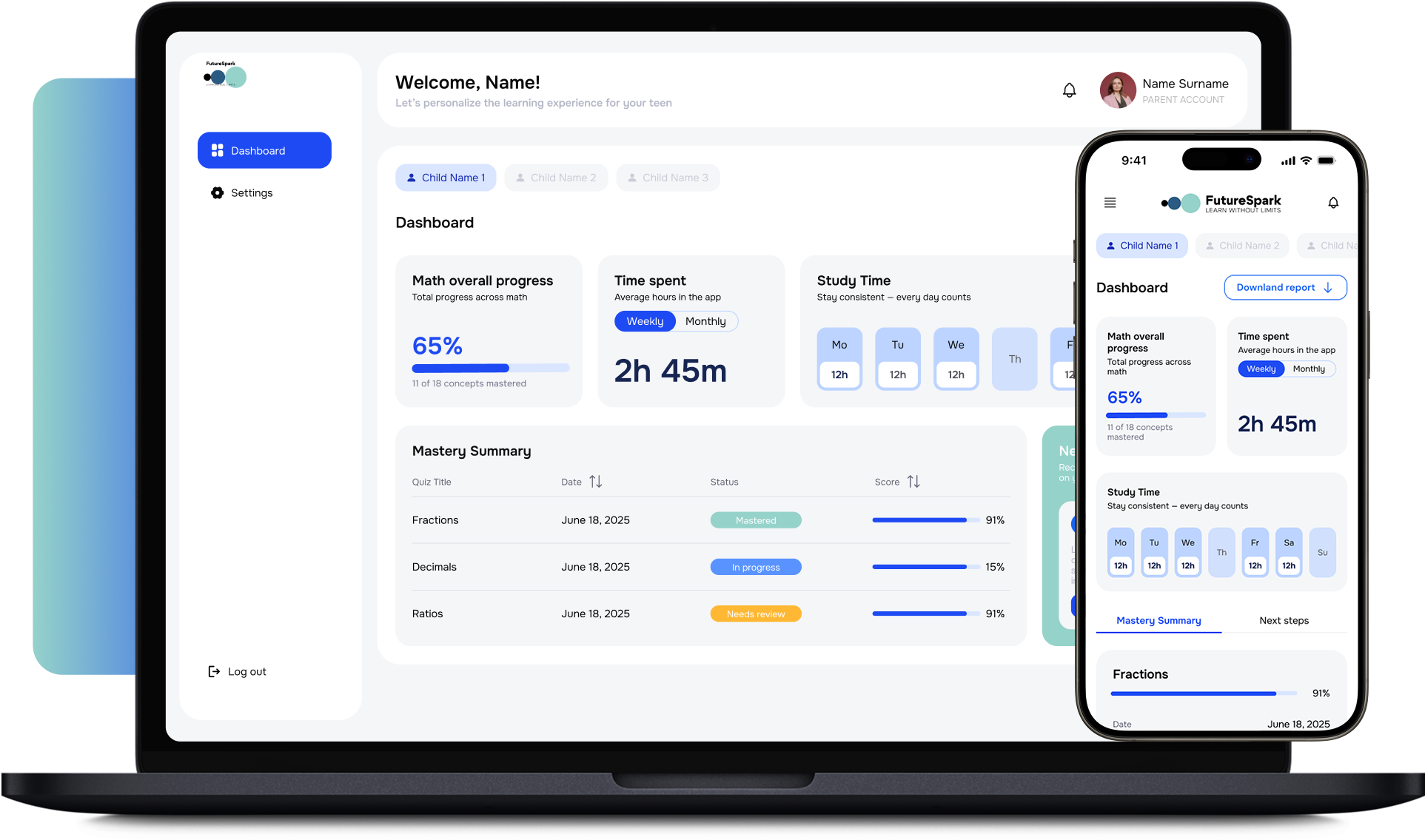
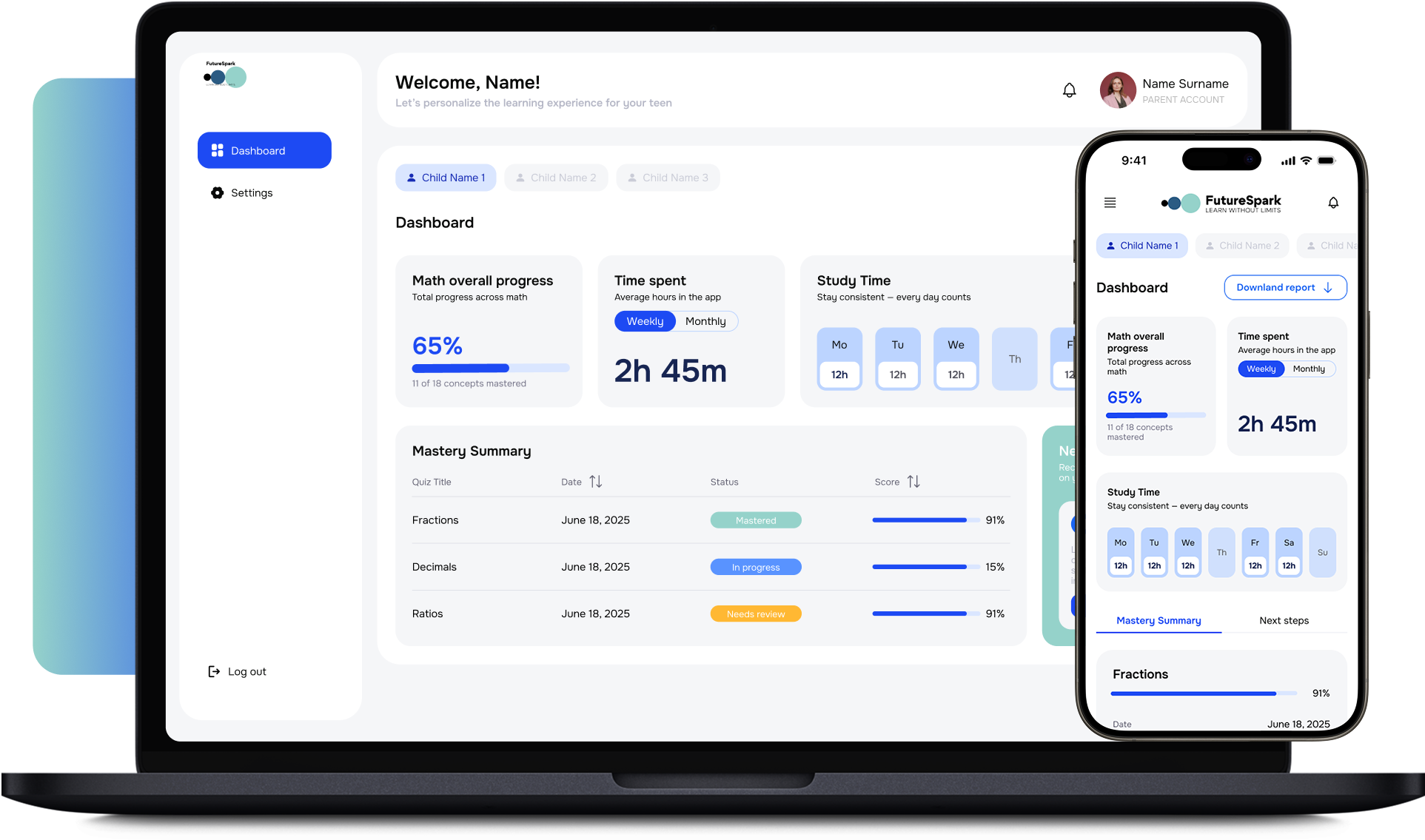
AI-powered learning + coaching platform with subject-specific mentoring modules and parent dashboards. Multi-turn agent with long-term memory.
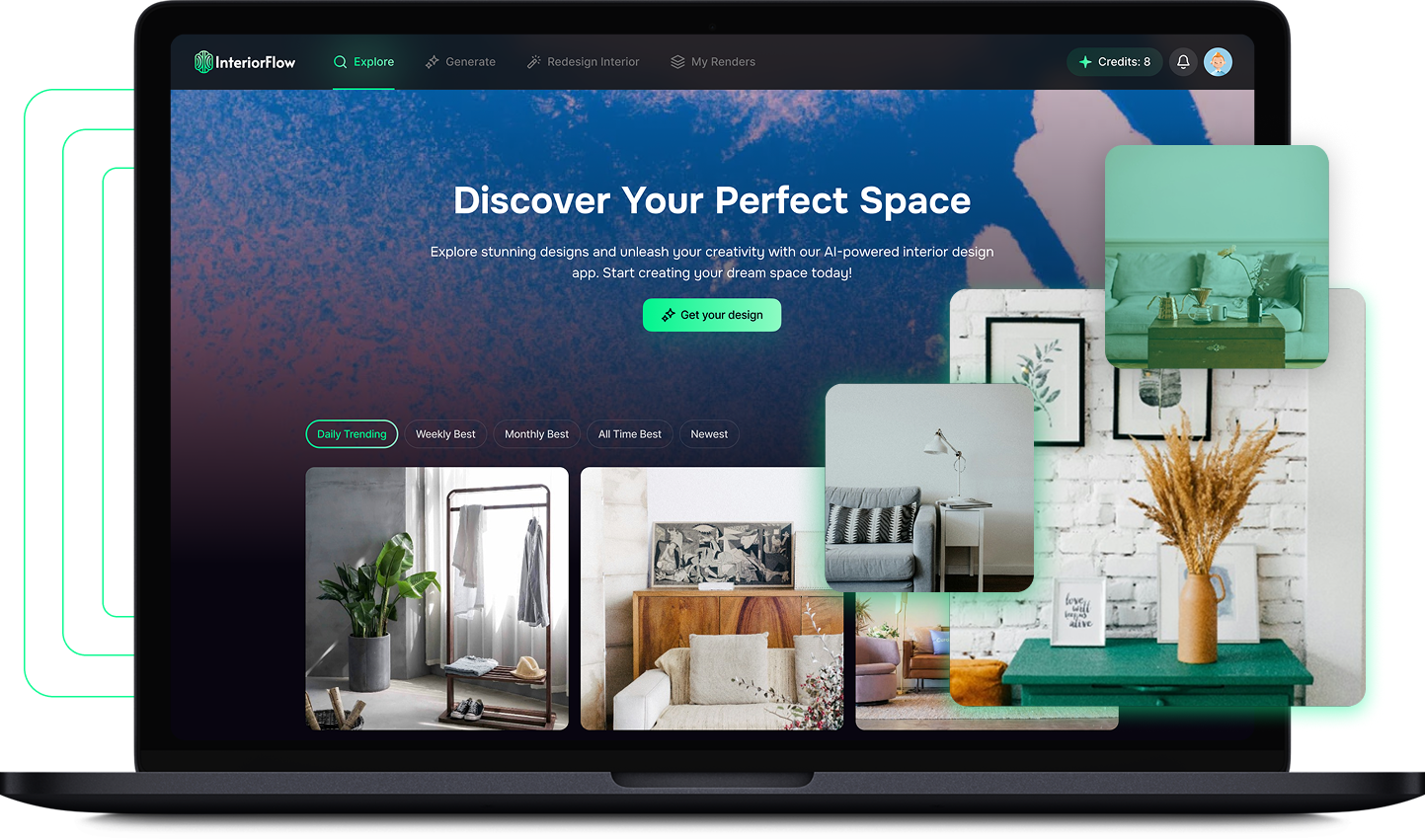
Upload a room photo, get redesigned renders in seconds. Style transfer, object detection, product recommendations with affiliate links.
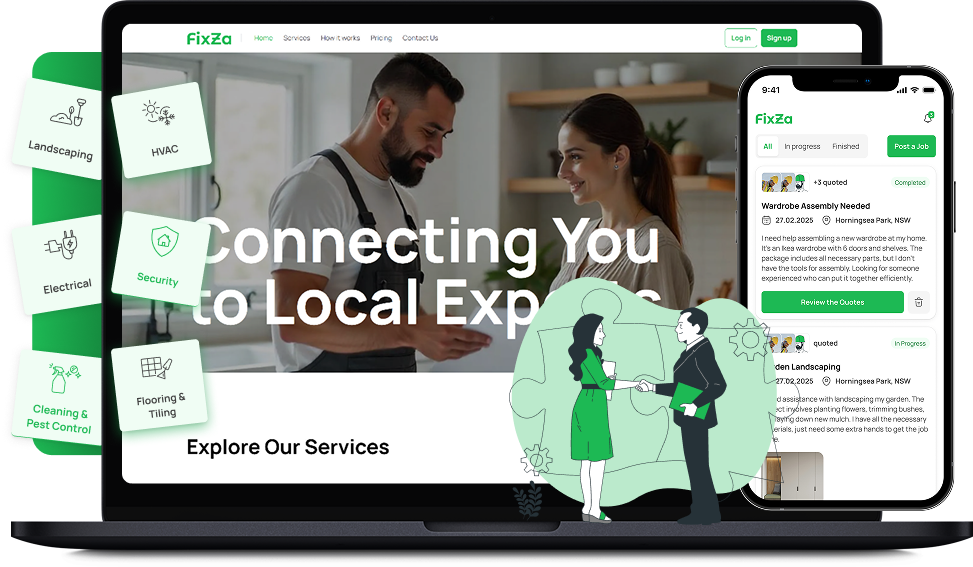
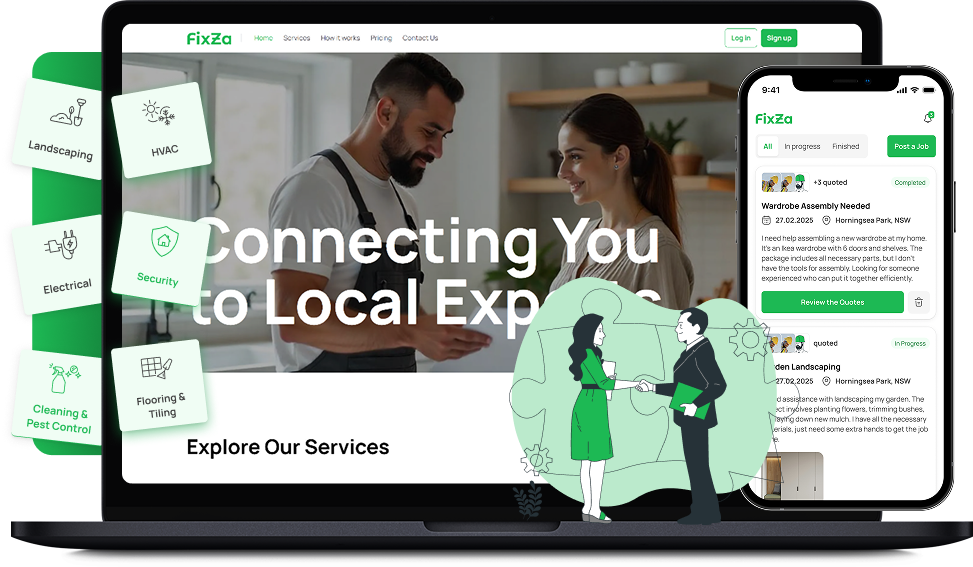
Two-sided repair marketplace matching customers with vetted technicians. Smart routing, real-time chat, and automated follow-ups.
We define the agent's boundary: what it's allowed to touch, what tools and APIs it needs, and what happens when it's wrong. Agent failure modes are different from chatbot failure modes — a chatbot that hallucinates gives a bad answer; an agent that hallucinates takes a bad action. We map every action surface and build the failure-mode inventory before writing code.
We build a narrow-scope agent first — one workflow, one tool set, human-in-the-loop on every action. We measure task-completion rate against your real data before expanding scope. If the agent can't reliably complete the narrow task, adding more capabilities won't fix it. A focused agent that does one thing well is worth more than a general-purpose agent that does ten things unreliably.
Framework choice depends on the problem: LangGraph for stateful multi-step workflows, Claude's native tool use for simpler orchestration, custom orchestration when off-the-shelf frameworks add complexity without value. Observability and tracing ship on day one — not as an afterthought. Every agent call is logged with input, tool selections, outputs, and cost. Retries, fallbacks, and timeout handling are first-class concerns.
Your team gets the runbook, the eval harness, and full ownership of prompts and tool definitions. Agents evolve faster than static software — new models, new tool capabilities, new edge cases from production traffic. The eval harness lets your team measure whether prompt changes improve or regress task-completion rate without guessing. We include cost monitoring dashboards, because agent systems that call models in loops can generate surprising bills.
Hear it straight from our customers.
This system has been a dream of mine for almost a year. I have tried to build it myself and finally came to the conclusion I needed help. The NerdHeadz team has built me exactly what I was dreaming about and more! Working with them has been an absolute pleasure. I can't thank them enough.
We take on tough challenges and turn them into simple, effective solutions for you.
We build fast, reliable apps that perfectly fit your project requirements.
Our solutions grow and adapt alongside your business, helping you stay ahead.
We maintain open communication and work with you every step of the way.
Depending on what you're actually building, one of these may fit better.
Ask our demo agent about scope, cost, and timelines. Hands you off to a human if you want.
Open the agent →30 minutes with one of our AI engineers. Scoped proposal back within 48 hours.
Pick a time →