01 / 05
pgvector & Hybrid Search
Embeddings stored in the same Postgres tables as relational data. Vector similarity scoped to a tenant in one SELECT statement, no sync layer to maintain.
We use Supabase when teams would otherwise wire Postgres + Pinecone + Pusher + Vercel Functions as four separate services. One Postgres, one billing line, one set of credentials.
Supabase is how we ship products that would otherwise stitch together Postgres, Pinecone or Qdrant, Pusher or Ably, and Cloudflare Workers or Vercel Functions as four separate services. The platform collapses those four onto one Postgres database — pgvector for embeddings, LISTEN/NOTIFY over WebSocket for subscriptions, Deno-runtime Edge Functions with built-in connection pooling, all backed by Row Level Security policies that double as the auth layer. The architectural payoff is concrete: a single SQL query can join relational data with vector search results, scoped to a tenant via the same WHERE clause that gates the rest of the app. One billing relationship, one credential surface, one place to look when something breaks.

One Postgres for what used to take four separate services. Vector search, real-time, auth, and edge functions on a single tenant — one billing line, one set of credentials.
Embeddings stored in the same Postgres tables as relational data. Vector similarity scoped to a tenant in one SELECT statement, no sync layer to maintain.
Postgres change events surfaced as WebSocket subscriptions. Clients only receive rows their RLS policies permit — auth becomes the subscription scoping layer.
Webhook handlers, secret-keeping API proxies, cron jobs running on the Deno runtime with Postgres connection pooling already wired.
Row Level Security policies expressed in SQL govern row visibility, write permissions, and storage uploads. One policy gates database and storage in the same breath.
The CLI's db diff produces SQL diff files. PR-reviewable, env-promotable, no admin-UI surprises slipping into production.
A typical modern SaaS reaches for four distinct backends: a relational database (RDS Postgres, Neon, or your own VM), a vector database (Pinecone, Qdrant, Weaviate) for semantic search and RAG, a real-time service (Pusher, Ably, Socket.io) for live updates, and an edge compute layer (Vercel Functions, Cloudflare Workers, Lambda) for the things origin shouldn't handle. That is four billing relationships, four sets of credentials to rotate, four sync patterns to keep aligned, and four places to debug a silent failure.
Supabase collapses all four onto Postgres. The pgvector extension stores embeddings in the same tables that hold relational data. Postgres LISTEN/NOTIFY exposed over WebSocket handles real-time. Deno-runtime Edge Functions run at the edge with database connection pooling already wired.
The concrete win shows up in queries: SELECT * FROM documents WHERE team_id = $1 ORDER BY embedding <=> $2 LIMIT 10. Vector similarity scoped to a tenant in one statement, no sync layer to maintain.

A working consolidation pattern is not a universal answer. Real cases where we choose differently:
- Massive vector workloads. Pinecone or Qdrant beat pgvector past tens of millions of vectors with high-QPS demands. Their dedicated indexing layers were built for that scale; pgvector reaches its ceiling sooner. - Self-hosted compliance regimes. Supabase Cloud is the simple path. Self-hosted Supabase exists, but operating six services in production (Postgres, Auth, Realtime, Storage, Functions, dashboard) is non-trivial. For HIPAA-strict teams already running their own Postgres, raw Postgres plus targeted tooling wins. - Strict multi-region writes. Supabase is single-primary by default. Globally-distributed write workloads belong on Aurora Global or CockroachDB. - Teams allergic to SQL. RLS policies, triggers, and views are how production Supabase apps are built. Avoidance fights the platform.
If a build maps onto one of these, we say so before recommending Supabase. Selling consolidation when the workload demands a separate vector layer just creates a second migration in twelve months.
How we use the platform on real engagements:
- Vector + relational in one query. Embeddings live in a column of the same table that holds the row's metadata. A "find documents similar to this one, but only ones owned by my team" query is one SELECT, not a two-system orchestration. Pairs naturally with our AI development services when the build is RAG-shaped.
- Real-time subscriptions scoped by RLS. Clients subscribe to a table; Postgres only emits rows that the user's RLS policies permit. Auth becomes the subscription scoping layer — no separate channel abstraction to keep aligned with permissions.
- Edge Functions for AI proxying. Keeps OpenAI or Anthropic API keys off the client without spinning up a Node service. Deno runtime, fast cold starts, Postgres connection pooling built in. We use them for streaming AI responses to Next.js frontends with per-user rate limiting via RLS-aware queries.
- Storage with RLS-scoped policies. File uploads gated by the same policies that gate database rows. "User can upload to folders matching their team_id" is one policy, not a separate auth integration.
- Migrations in Git. The CLI's db diff produces SQL diff files — PR-reviewable, env-promotable, no admin-UI surprises slipping into production.
Each row of the four-service collapse has a real trade-off. Honest version:
Relational data. Traditional: Postgres on RDS, Neon, or your own VM. Supabase equivalent: hosted Postgres with the same dialect. What you give up: nothing structural — you gain auth, REST + GraphQL APIs, and a dashboard for free.
Vector search. Traditional: Pinecone, Qdrant, or Weaviate as a separate service with its own SDK and billing. Supabase equivalent: the pgvector extension on the same Postgres. What you give up: peak QPS at >10M-vector scale. pgvector handles smaller workloads cleanly; switch to a dedicated layer past that — see our vector database notes for when.
Real-time subscriptions. Traditional: Pusher, Ably, or Socket.io with a separate auth integration. Supabase equivalent: Postgres LISTEN/NOTIFY surfaced over WebSocket with RLS-scoped subscriptions. What you give up: presence and typing-indicator features are doable but require more glue than Pusher's out-of-box.
Edge compute. Traditional: Vercel Functions, Cloudflare Workers, or AWS Lambda — separate deploy pipeline, separate observability surface. Supabase equivalent: Edge Functions on Deno with built-in DB connection pooling. What you give up: global distribution. Edge Functions run regional, not as wide as Cloudflare's edge.
Auth. Traditional: Auth0, Clerk, or Cognito — separate billing, separate user store synced with the database. Supabase equivalent: built-in auth where users live in the same Postgres. What you give up: the most polished hosted UI flows. Supabase's are good; Clerk's are better.
None of these trade-offs is fatal in isolation. The decision becomes uncomfortable only when a build sits on a boundary — vector workload approaching ten million rows, or multi-region writes that have not crystallized in the spec yet. Those calls are workload-specific; the honest version comes out of looking at the actual query patterns and growth trajectory, not the architecture diagram.
It works well for a specific set of problem shapes — and fails predictably on others.
Postgres + Pinecone + Pusher + Vercel Functions collapses into one tenant. One billing line, one set of credentials, one place to debug a silent failure.
Pinecone or Qdrant beat pgvector at high-QPS scale. Their dedicated indexing layers were built for that envelope; pgvector reaches its ceiling sooner.
Supabase is single-primary by default. Globally-distributed write workloads belong on Aurora Global or CockroachDB.
Embeddings stored in the same Postgres tables as relational data. Vector similarity joins with WHERE clauses, scoped by tenant via Row Level Security. No sync layer between a vector DB and your application database.
Postgres change events surfaced as WebSocket subscriptions. Clients only receive rows their RLS policies permit, so the auth layer doubles as the subscription scoping layer — no separate channel abstraction to keep in sync with permissions.
Webhook handlers, AI proxying, and cron jobs running on the Deno runtime with Postgres connection pooling pre-wired. Keeps API keys off the client and avoids the cold-start pain of a fresh Postgres connection from a serverless function.
RLS policies expressed in SQL govern row visibility, write permissions, and storage access. One policy file becomes the source of truth for who-can-see-what, instead of duplicating auth logic across REST handlers and frontend guards.
The Supabase CLI produces SQL diff files via db diff — PR-reviewable, env-promotable, no admin-UI changes slipping into production unnoticed. Schema becomes a Git artifact, not a dashboard state.
RLS-scoped real-time subscriptions and pgvector-driven discovery in a single Postgres. Editorial layer plus auth plus search in one query plane.
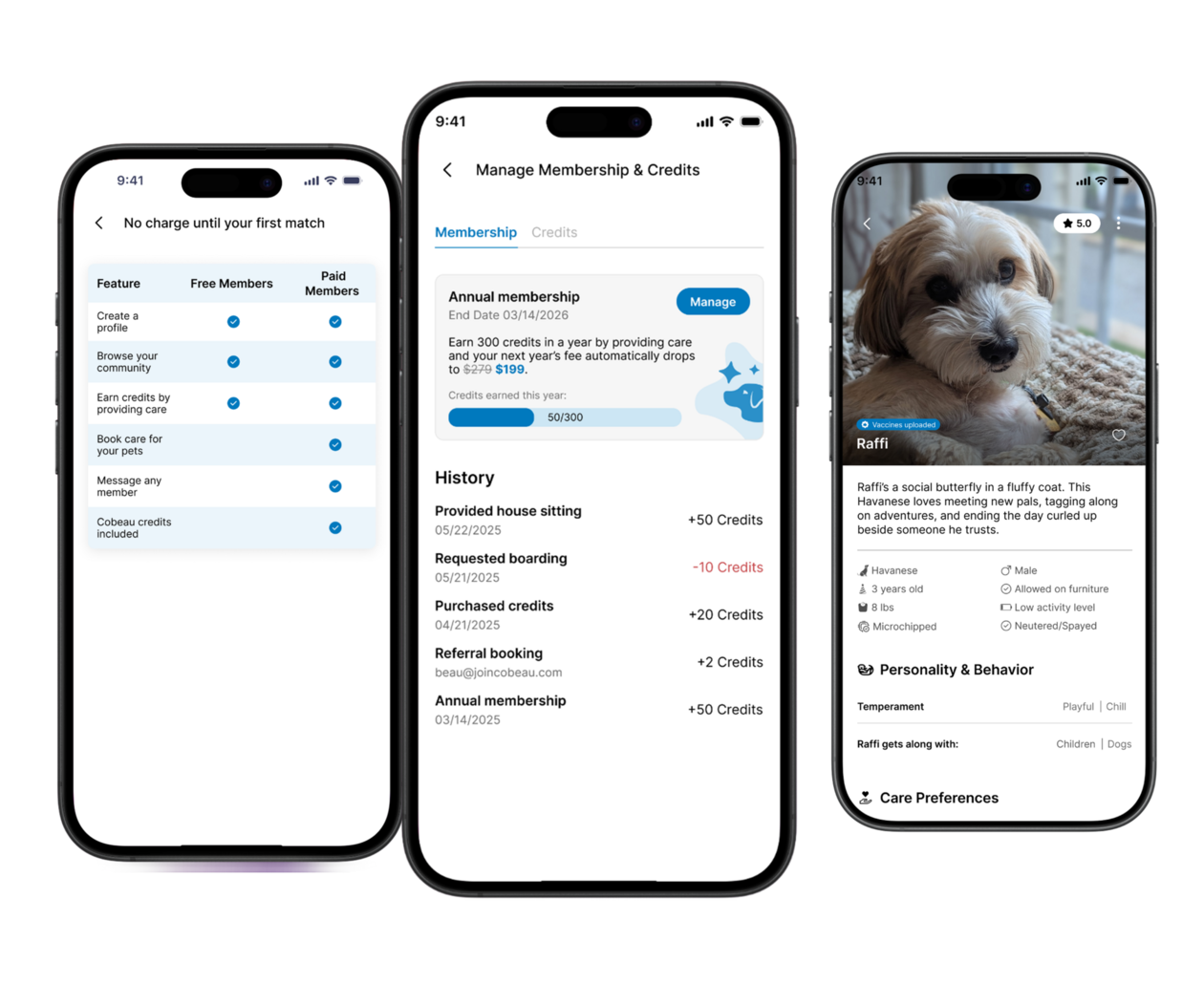
Two-sided marketplace with auth, real-time updates, and RLS policies governing both database rows and storage uploads.
Map the current 4-service architecture (relational + vector + real-time + edge). Identify which workloads consolidate cleanly versus which justify staying separate.
Tables, relationships, vector indexes. RLS policies expressed in SQL with test coverage on the critical visibility paths.
Real-time subscriptions, edge functions, storage policies. Migrations in Git from day one. Frontend wired with the supabase-js client.
Migrations runbook, RLS testing patterns, and we monitor the first migration deploys for fourteen days post-launch.
Hear it straight from our customers.
This system has been a dream of mine for almost a year. I have tried to build it myself and finally came to the conclusion I needed help. The NerdHeadz team has built me exactly what I was dreaming about and more! Working with them has been an absolute pleasure. I can't thank them enough.
We take on tough challenges and turn them into simple, effective solutions for you.
We build fast, reliable apps that perfectly fit your project requirements.
Our solutions grow and adapt alongside your business, helping you stay ahead.
We maintain open communication and work with you every step of the way.
Depending on what you're actually building, one of these may fit better.
Ask our demo agent about scope, cost, and timelines. Hands you off to a human if you want.
Open the agent →30 minutes with one of our AI engineers. Scoped proposal back within 48 hours.
Pick a time →