01 / 05
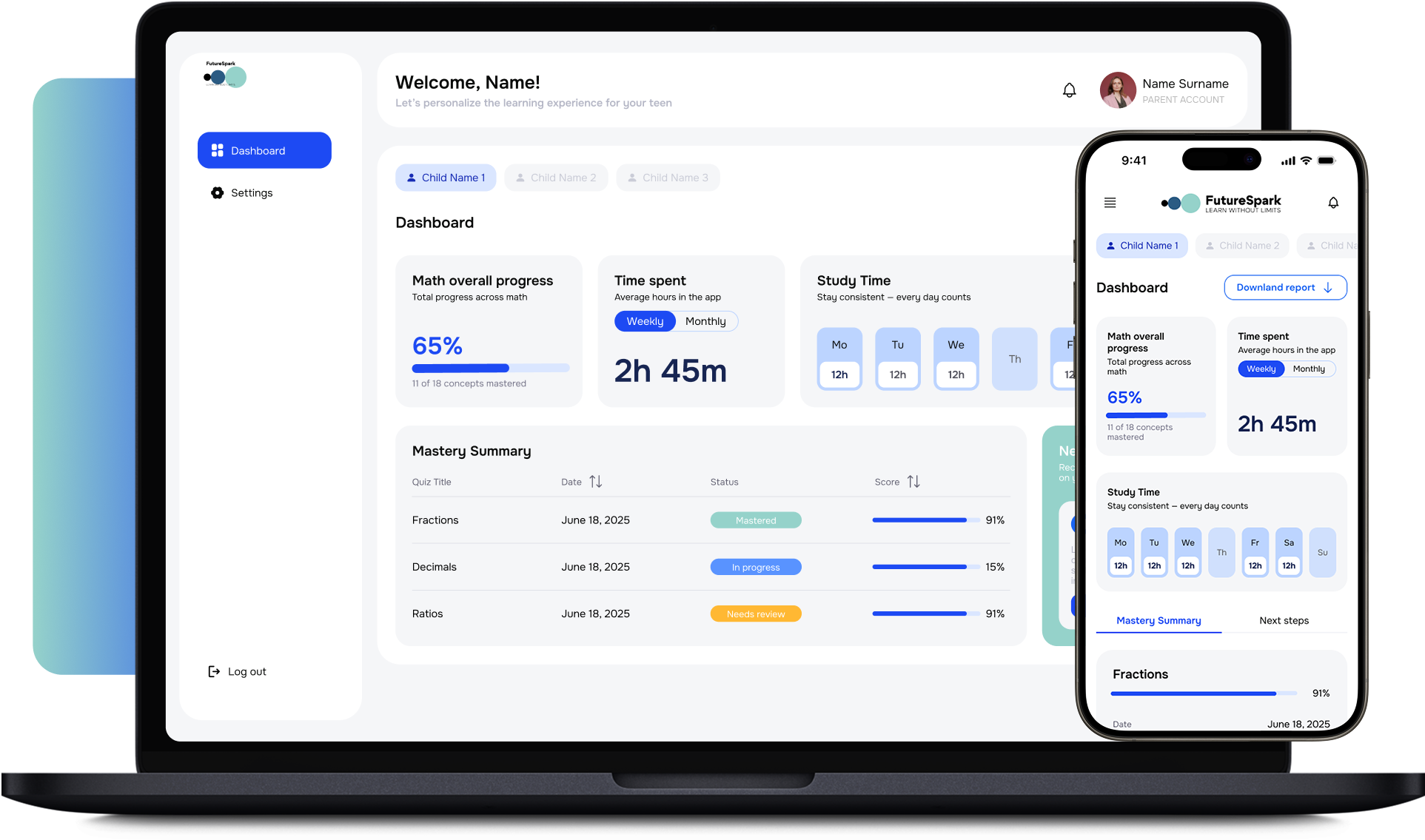
Python Sidecar Architecture
FastAPI runs as its own pm2 unit alongside Node. Shared physical infra, separate process spaces, independent restart cycles.
FastAPI is how we add Python's ML ecosystem — langchain, transformers, model servers — without dragging Python into the Node process. Sidecar service, HTTP boundary, type-safe.
NerdHeadz product builds run TypeScript end-to-end — Next.js, Node, Payload CMS, shared types. AI work breaks that uniformity, because the Python ML ecosystem (langchain, transformers, sentence-transformers, vllm, scikit-learn) trails its JavaScript equivalents on capability and community. The naive answer is to spawn Python from Node via subprocess. It works for prototypes and breaks under load. Our pattern: a FastAPI service running as a sidecar process, talked to over HTTP, with Pydantic models matching the TypeScript types on the Node side. The Python service owns its dependencies and deploys independently. Type-checked at the HTTP boundary via Pydantic-to-TypeScript codegen, so contract drift between the Python and Node sides becomes a build error, not a runtime one.

Python sidecars for ML, not Python in the Node process. FastAPI on its own port behind the same Cloudflare Tunnel — type-safe at the HTTP boundary, independently deployed.
FastAPI runs as its own pm2 unit alongside Node. Shared physical infra, separate process spaces, independent restart cycles.
Generated types at the HTTP boundary so the Node app's calls to FastAPI are type-checked. Drift becomes a build error, not a runtime surprise.
Async-first design pairs cleanly with SSE for token-by-token AI output. We use it for streaming Anthropic and OpenAI responses to Next.js frontends.
Each FastAPI service runs in its own virtualenv. Costs disk; eliminates entire categories of "this version of torch broke that transformers" bugs.
Same security posture as the Node app — TLS termination, DDoS mitigation, zero exposed origin.
Most NerdHeadz product builds are TypeScript end-to-end — Next.js frontend, Node backend, Payload CMS, all sharing types and one runtime. AI work disrupts that uniformity. Langchain matters in Python. So do the Hugging Face transformers ecosystem, sentence-transformers for embeddings, vllm for self-hosted inference, scikit-learn for classical ML pipelines. The JavaScript equivalents exist but lag on capability and community size.
The naive answer is to call Python from Node via subprocess or child_process. That works for prototypes and breaks under load — process spawning is slow, error handling is fragile, dependency management gets ugly fast as the Python tree grows.
The cleaner answer is an HTTP boundary. FastAPI runs as its own service. The Node app calls it over HTTP. Each side owns its dependencies, deploys independently, restarts independently. We use this pattern on this site: estimation-api handles deal pricing logic with structured AI output, content-api drives content generation workloads. Both run as separate Python processes on the same box as the Next.js app, fronted by the same Cloudflare Tunnel.

A working pattern is not a universal answer. Cases where we don't reach for it:
- No Python in the build. If there is no langchain, no transformers, no Python ML library doing real work, FastAPI is overhead. Node handles HTTP and JSON fine. Do not add a runtime to host code that could run in the existing one. - Massive sustained traffic. FastAPI is fast for Python (uvicorn + async), but Python's GIL caps throughput per process. Heavy traffic means horizontal scaling and operational work that Node sidesteps. - Latency-critical request paths. Python cold starts and GIL coordination add tail latency. Sub-50ms p99 budgets are easier to hit on Node or Go. - Teams without Python ops fluency. A Python service in production needs someone who can debug GIL contention, dependency hell, and the difference between async libraries that yield and ones that block. If the team is JS-only, the operational tax is real.
If the answer is 'we just want better types in our Node API,' the answer is TypeScript, not FastAPI.
Concrete patterns from the estimation-api and content-api work:
- Sidecar process, not subprocess. Each FastAPI service runs as its own pm2 or systemd unit on the same box. The Node app talks to it over loopback HTTP. Shared physical infra, separate process spaces, independent restart cycles. - Pydantic models match the TypeScript types. We generate TS interfaces from Pydantic models (or vice versa, depending on which side is the source of truth) so the Node app's calls to FastAPI are type-checked at the boundary. Drift becomes a build error instead of a runtime surprise. - Async-by-default for streaming. FastAPI's async support pairs cleanly with streaming AI responses. We use it for SSE (server-sent events) when the frontend wants tokens as they generate, not after the full response. - Dependency isolation via virtualenv. Each service has its own venv. Costs 200MB of disk per service; saves entire categories of "this version of torch broke that version of transformers" bugs. - OpenAPI specs from type hints. FastAPI auto-generates OpenAPI from Python type annotations — useful in development for the build pipeline that produces frontend types. Production exposure of the docs UI is a separate decision behind auth. - Independent deploys. Updating estimation-api does not restart Next.js. Updating Next.js does not restart estimation-api. Two subdomains, two processes, one routing layer.
Our AI development services lean on this pattern when Python is the inference layer, with OpenAI or other providers handling the actual model calls.
Each architectural choice in a Python sidecar setup. Default → sidecar version → what we do.
Where does the Python code live? Default: subprocess from Node, or a separate language service in a separate cloud. Sidecar: same box as Node, separate process, talked to over HTTP. What we do: same-box sidecar is cheaper, faster (loopback HTTP is microseconds), and easier to operate than a remote service. Separate cloud only when the Python service needs different scaling characteristics.
How do types stay aligned? Default: hope. Sidecar: generate TypeScript types from Pydantic models, or vice versa. What we do: type sync at the boundary catches an entire class of bugs. The tooling is mature (datamodel-code-generator, openapi-typescript) and the build step is cheap.
How does the Node app find the FastAPI service? Default: hardcoded URLs in env vars. Sidecar on same box: localhost loopback. Cross-box: Cloudflare Tunnel hostname plus an auth header. What we do: localhost when same box, Tunnel when not. We do not introduce service discovery (Consul, etc.) for two-service architectures — overkill.
How does deployment work? Default: one CI pipeline, one deploy. Sidecar: each service has its own deploy lifecycle. What we do: independent deploys per service, coordinated when API contracts change. The boundary makes coordination explicit instead of implicit.
What about observability? Default: one log stream, one metrics surface. Sidecar: each service emits its own. What we do: tag logs with the service name and route them to the same destination. Two streams, one pane of glass. Do not fragment monitoring just because the processes split.
It works well for a specific set of problem shapes — and fails predictably on others.
langchain, transformers, sentence-transformers, vllm — Python ecosystem matters. FastAPI keeps Python out of the Node process while keeping the HTTP boundary clean.
Python cold starts and GIL coordination add tail latency. Easier to hit on Node or Go. Use FastAPI when the ML payoff is worth the budget.
If there is no langchain, no transformers, no Python doing real ML work, FastAPI is overhead. Node handles HTTP and JSON fine.
FastAPI runs as its own process alongside Node, on the same box or cross-box. The Node app talks to it over HTTP. Separate process spaces, independent restarts, no subprocess fragility.
Generated types at the HTTP boundary so the Node app's calls to FastAPI are checked at build time. Pydantic models become TS interfaces (or vice versa) via datamodel-code-generator and openapi-typescript.
FastAPI's async-first design pairs cleanly with SSE for token-by-token AI output. The frontend gets the response as it generates, not after the whole completion lands.
Each FastAPI service runs in its own virtualenv. Costs disk; eliminates the category of bugs where one library version breaks another's installation. Painful Python dependency math becomes a build-time concern.
Same security posture as the Node app — TLS termination, DDoS mitigation, zero exposed origin. The Python service inherits the routing layer, not a separate ingress story.
Python sidecar handles voice agent orchestration with streaming responses to a Node frontend. Independent deploy lifecycles for the AI layer.
FastAPI service for editorial-AI workloads — content generation, embedding pipelines, structured output. Cloudflare Tunnel fronted.
Identify the Python ML surface — which libraries are doing real work, which workflows justify a separate process, which are fine in Node.
pm2 unit, Tunnel route, Pydantic models for the boundary. Type generation pipeline wired so the Node app sees the FastAPI surface as typed.
Streaming endpoints, dependency isolation per service, OpenAPI specs from type hints. Frontend wired with SSE for token-by-token output.
Sidecar runbook, GIL-debugging primer, and we stay paged for the first 14 days of production AI traffic.
Hear it straight from our customers.
This system has been a dream of mine for almost a year. I have tried to build it myself and finally came to the conclusion I needed help. The NerdHeadz team has built me exactly what I was dreaming about and more! Working with them has been an absolute pleasure. I can't thank them enough.
We take on tough challenges and turn them into simple, effective solutions for you.
We build fast, reliable apps that perfectly fit your project requirements.
Our solutions grow and adapt alongside your business, helping you stay ahead.
We maintain open communication and work with you every step of the way.
Depending on what you're actually building, one of these may fit better.
Ask our demo agent about scope, cost, and timelines. Hands you off to a human if you want.
Open the agent →30 minutes with one of our AI engineers. Scoped proposal back within 48 hours.
Pick a time →